How can you efficiently manage large SQL datasets? With "partition by multiple columns SQL"!
Partitioning a table by multiple columns involves dividing the table into smaller, more manageable chunks based on the values in the specified columns. This technique offers significant performance benefits, particularly for queries that access data from specific partitions. By leveraging multiple columns, you can create a more granular partitioning scheme, optimizing data retrieval and reducing query execution time.
The advantages of partitioning by multiple columns are numerous. Improved query performance is at the forefront, as it enables faster data retrieval by directing queries to specific partitions that contain the relevant data. Additionally, it enhances data management by simplifying maintenance tasks such as data loading and deletion, which can be performed on a partition-by-partition basis. This granular control also facilitates efficient data backups and recovery, allowing you to restore only the affected partitions in case of data loss.
Historically, database systems have employed partitioning techniques to handle large datasets. The concept of partitioning by multiple columns has evolved over time, with modern database management systems offering advanced partitioning capabilities. This has made it an essential strategy for optimizing the performance and manageability of large SQL databases.
In this article, we will delve deeper into the world of partitioning by multiple columns in SQL. We will explore its benefits, implementation techniques, best practices, and common use cases. Join us on this journey to unlock the power of partitioning and revolutionize your data management strategies!
Partition by Multiple Columns SQL
Partitioning by multiple columns in SQL is a powerful technique for managing large datasets efficiently. It involves dividing a table into smaller, more manageable chunks based on the values in the specified columns. This approach offers significant performance benefits, particularly for queries that access data from specific partitions.
- Data Organization: Partitioning allows data to be organized logically, improving data retrieval efficiency.
- Query Optimization: Queries can be directed to specific partitions, reducing query execution time.
- Data Management: Maintenance tasks like data loading and deletion can be performed on a partition-by-partition basis.
- Scalability: Partitioning enables horizontal scaling by distributing data across multiple servers.
- Concurrency: Partitions can be accessed concurrently by multiple users, improving concurrency and reducing locking.
These key aspects work together to enhance the performance and manageability of large SQL databases. For example, consider a table with billions of rows partitioned by date and region. A query that retrieves data for a specific date range and region can be directed to the relevant partition, significantly reducing the amount of data that needs to be processed. Additionally, data loading operations can be performed on a specific partition without affecting the rest of the table, minimizing downtime and improving data integrity.
Data Organization
In the context of "partition by multiple columns SQL," data organization plays a crucial role in optimizing data retrieval efficiency. By partitioning a table based on multiple columns, data is logically organized into smaller, more manageable chunks. This structured organization enables queries to be directed to specific partitions, significantly reducing the amount of data that needs to be processed. As a result, query execution time is minimized, leading to improved overall performance.
- Data Locality: Partitioning ensures that related data is stored together on the same physical storage unit. This data locality allows for faster data retrieval as the database can access the required data from a specific partition without having to search the entire table.
- Reduced I/O Operations: By directing queries to specific partitions, partitioning reduces the number of I/O operations required to retrieve data. This is because the database only needs to read data from the relevant partition, rather than the entire table.
- Improved Cache Utilization: Partitioning improves cache utilization by keeping frequently accessed data in memory. As queries are directed to specific partitions, the database can cache the data from those partitions, reducing the need to retrieve data from the disk.
- Simplified Data Management: Data organization through partitioning simplifies data management tasks such as data loading, deletion, and updates. These operations can be performed on a partition-by-partition basis, minimizing the impact on the rest of the table.
In summary, the logical organization of data through partitioning by multiple columns SQL is a key factor in improving data retrieval efficiency. By structuring data into smaller, manageable chunks, queries can be optimized to access only the relevant data, leading to reduced query execution time and improved overall database performance.
Query Optimization
In the realm of "partition by multiple columns SQL," query optimization takes center stage. By partitioning a table based on multiple columns, queries can be directed to specific partitions, significantly reducing query execution time. This optimization technique is particularly beneficial for large datasets, where searching through the entire table can be a time-consuming process.
- Partition Pruning
Partition pruning is a powerful technique that leverages partitioning to eliminate unnecessary partitions from the query execution plan. By analyzing the query predicate and the partition key columns, the database can identify and exclude partitions that do not contain any relevant data. This selective approach dramatically reduces the amount of data that needs to be scanned, leading to significant performance gains.
- Partition Elimination
Partition elimination is another optimization technique that utilizes partitioning to further refine the query execution plan. When a query predicate is highly selective and matches only a specific partition, the database can eliminate all other partitions from consideration. This technique is particularly effective when combined with partition pruning, as it allows the database to narrow down the search space even further.
- Index Partitioning
Index partitioning involves creating separate indexes for each partition. This technique improves query performance by allowing the database to use the appropriate index for each partition. By eliminating the need to scan the entire index, index partitioning significantly reduces I/O operations and speeds up query execution.
- Cache Optimization
Partitioning can also be leveraged to optimize cache utilization. By keeping frequently accessed data in smaller partitions, the database can cache the data more effectively. This reduces the number of disk accesses required to retrieve data, resulting in faster query execution times.
In summary, the ability to direct queries to specific partitions is a cornerstone of query optimization in "partition by multiple columns SQL." By employing techniques such as partition pruning, partition elimination, index partitioning, and cache optimization, databases can significantly reduce query execution time and improve overall performance, making them ideal for managing large datasets and supporting complex queries.
Data Management
In the context of "partition by multiple columns SQL," data management takes on a new level of efficiency with the ability to perform maintenance tasks on a partition-by-partition basis. This granular approach offers significant advantages for managing large datasets, simplifying tasks such as data loading, deletion, and updates.
Consider a large table with billions of rows partitioned by date and region. Without partitioning, adding new data to the table would require a costly and time-consuming operation that affects the entire table. However, with partitioning, new data can be loaded into a specific partition, minimizing the impact on the rest of the table. Similarly, deleting outdated data can be performed on a partition-by-partition basis, ensuring efficient data cleanup without affecting other partitions.
The ability to manage data at the partition level not only simplifies maintenance tasks but also improves data integrity. By isolating operations to specific partitions, the risk of data corruption or inconsistencies is reduced. Additionally, it allows for concurrent maintenance tasks, as different users can work on different partitions without interfering with each other.
In summary, the ability to perform data management tasks on a partition-by-partition basis is a crucial aspect of "partition by multiple columns SQL." It simplifies maintenance operations, improves data integrity, and enables concurrent data management, making it an essential technique for managing large datasets efficiently.
Scalability
In the realm of "partition by multiple columns SQL," scalability takes center stage. Partitioning plays a pivotal role in enabling horizontal scaling, a technique for distributing data across multiple servers to handle increasing data volumes and concurrent access.
- Data Distribution
Partitioning allows data to be distributed across multiple servers, creating a distributed database system. This distribution alleviates the load on a single server, improving overall performance and scalability.
- Load Balancing
With data partitioned across multiple servers, incoming queries can be load-balanced, distributing the workload evenly. This load balancing ensures that no single server becomes overloaded, maintaining optimal performance.
- Fault Tolerance
In the event of server failure, a distributed database system can automatically reroute queries to other servers that hold the required data. This fault tolerance ensures high availability and data accessibility, even in the face of hardware issues.
- Linear Scalability
As data grows and the number of concurrent users increases, partitioning enables linear scalability. By adding more servers to the distributed system, the database can handle the increased load without compromising performance.
The scalability benefits of partitioning are particularly evident in data warehousing and online transaction processing (OLTP) systems, where data volumes are immense, and performance is critical. By partitioning data across multiple servers, these systems can handle massive workloads, ensuring fast and reliable access to data.
Concurrency
In the realm of "partition by multiple columns SQL," concurrency takes center stage. Partitioning plays a pivotal role in enhancing concurrency, the ability of a database system to handle multiple simultaneous requests without compromising performance.
When data is partitioned, each partition can be accessed independently by different users or processes. This eliminates the need for exclusive locks on the entire table, which can significantly improve concurrency and reduce the risk of deadlocks. As a result, multiple users can perform read and write operations on different partitions concurrently, maximizing resource utilization and overall throughput.
The benefits of improved concurrency are particularly evident in data warehousing and online transaction processing (OLTP) systems, where multiple users may be accessing and modifying data simultaneously. By partitioning data, these systems can ensure that concurrent operations do not interfere with each other, maintaining high levels of performance and data integrity.
Furthermore, partitioning can reduce the impact of locking on individual partitions. When a user modifies data in a specific partition, only that partition is locked, allowing other users to continue accessing and modifying data in other partitions. This fine-grained locking mechanism minimizes the potential for blocking operations and further enhances concurrency.
In summary, the ability to access partitions concurrently is a key aspect of "partition by multiple columns SQL." By eliminating exclusive locks on the entire table and reducing the impact of locking on individual partitions, partitioning significantly improves concurrency and enables multiple users to work with data simultaneously without compromising performance or data integrity.
Partition by Multiple Columns SQL
This section addresses common questions and misconceptions surrounding the concept of "partition by multiple columns SQL" to provide a comprehensive understanding of its functionality and benefits.
Question 1: What are the key benefits of partitioning a table by multiple columns?
Partitioning a table by multiple columns offers numerous advantages, including improved query performance, simplified data management, enhanced scalability, increased concurrency, and reduced locking.
Question 2: How does partitioning improve query performance?
Partitioning enables queries to be directed to specific partitions, reducing the amount of data that needs to be processed. This optimization technique significantly improves query execution time and overall database performance.
Question 3: What are the different types of partitioning techniques available in SQL?
SQL supports various partitioning techniques, including range partitioning, hash partitioning, list partitioning, and composite partitioning. Each technique has its own advantages and use cases, depending on the data distribution and query patterns.
Question 4: How does partitioning impact data management tasks?
Partitioning simplifies data management tasks such as data loading, deletion, and updates. These operations can be performed on a partition-by-partition basis, minimizing the impact on the rest of the table and improving data integrity.
Question 5: What are the scalability benefits of partitioning?
Partitioning enables horizontal scaling by distributing data across multiple servers. This distribution alleviates the load on a single server, improving overall performance and scalability as data volumes and concurrent access increase.
Question 6: How does partitioning improve concurrency in SQL databases?
Partitioning allows partitions to be accessed concurrently by multiple users or processes, eliminating the need for exclusive locks on the entire table. This significantly improves concurrency and reduces the risk of deadlocks, enabling multiple users to work with data simultaneously without compromising performance.
Summary: Partitioning by multiple columns SQL is a powerful technique that offers significant advantages for managing large datasets and improving database performance. By leveraging this technique, organizations can optimize query execution, simplify data management, enhance scalability, increase concurrency, and reduce locking, ultimately leading to a more efficient and effective data management system.
Transition to the next article section: To delve deeper into the practical implementation and best practices of partitioning by multiple columns in SQL, please refer to the following comprehensive guide...
Conclusion
Partitioning by multiple columns in SQL has proven to be a powerful technique for optimizing data management and improving database performance. By logically organizing data, optimizing queries, simplifying data management, enhancing scalability, increasing concurrency, and reducing locking, partitioning empowers organizations to handle large datasets efficiently.
As the volume and complexity of data continues to grow, partitioning will play an increasingly critical role in ensuring the efficient and effective management of data. By leveraging the capabilities of partitioning, organizations can unlock the full potential of their data and gain a competitive edge in today's data-driven landscape.
The Ultimate Guide To Different Types Of Languages
The Ultimate Guide To The Main Characters Of Your Favorite Books
AB-Negative And O-Positive Blood Groups: Understanding Compatibility And Transfusions
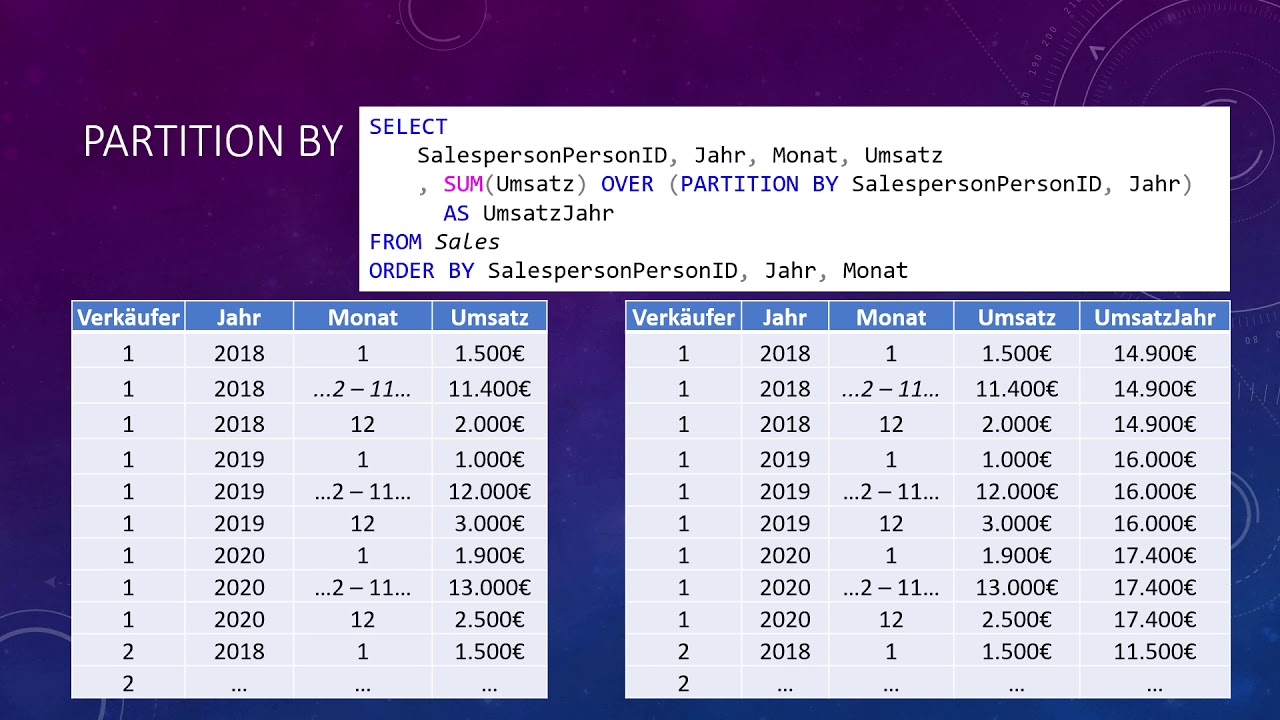
SQL PARTITION BY YouTube

SQL PARTITION BY Clause When and How to Use It
![[Solved] SQL Partition By Multiple Columns 9to5Answer](https://i2.wp.com/sgp1.digitaloceanspaces.com/ffh-space-01/9to5answer/uploads/post/avatar/212733/template_sql-partition-by-multiple-columns20220629-3190592-ukh7ob.jpg)
[Solved] SQL Partition By Multiple Columns 9to5Answer

